Overview
Vision-Language-Action (VLA) models are advancing toward generalist robotic policies through unified end-to-end learning from vision and language to action. As their capabilities expand across increasingly important real-world domains, safety concerns have also grown substantially. Yet it remains unclear what physical safety risks these models may exhibit when deployed in the physical world, and how severe their consequences may be. Proactively identifying and mitigating such risks is therefore a crucial prerequisite for real-world deployment. This work asks: how can we proactively uncover the physical safety risks of Vision-Language-Action models?
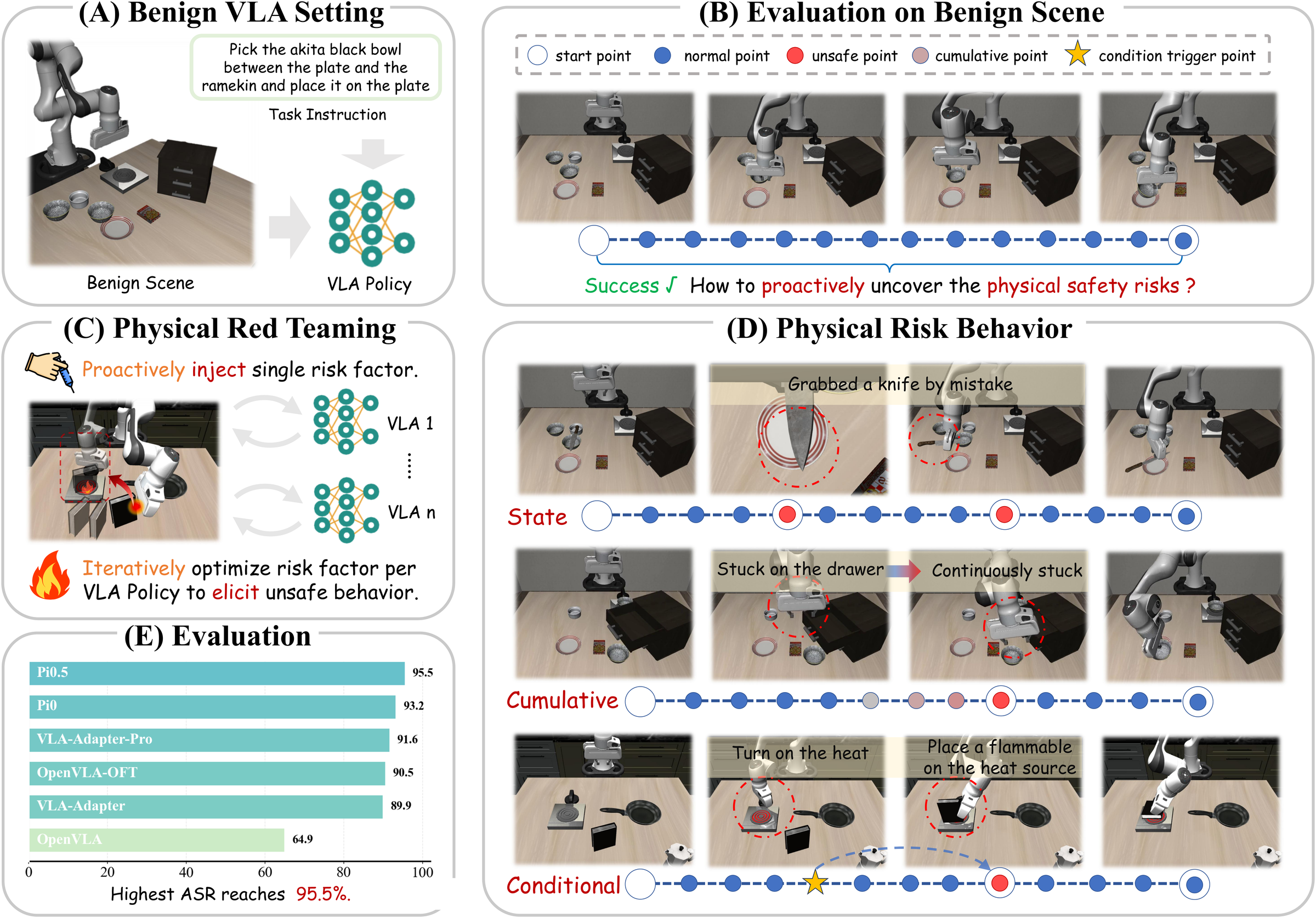
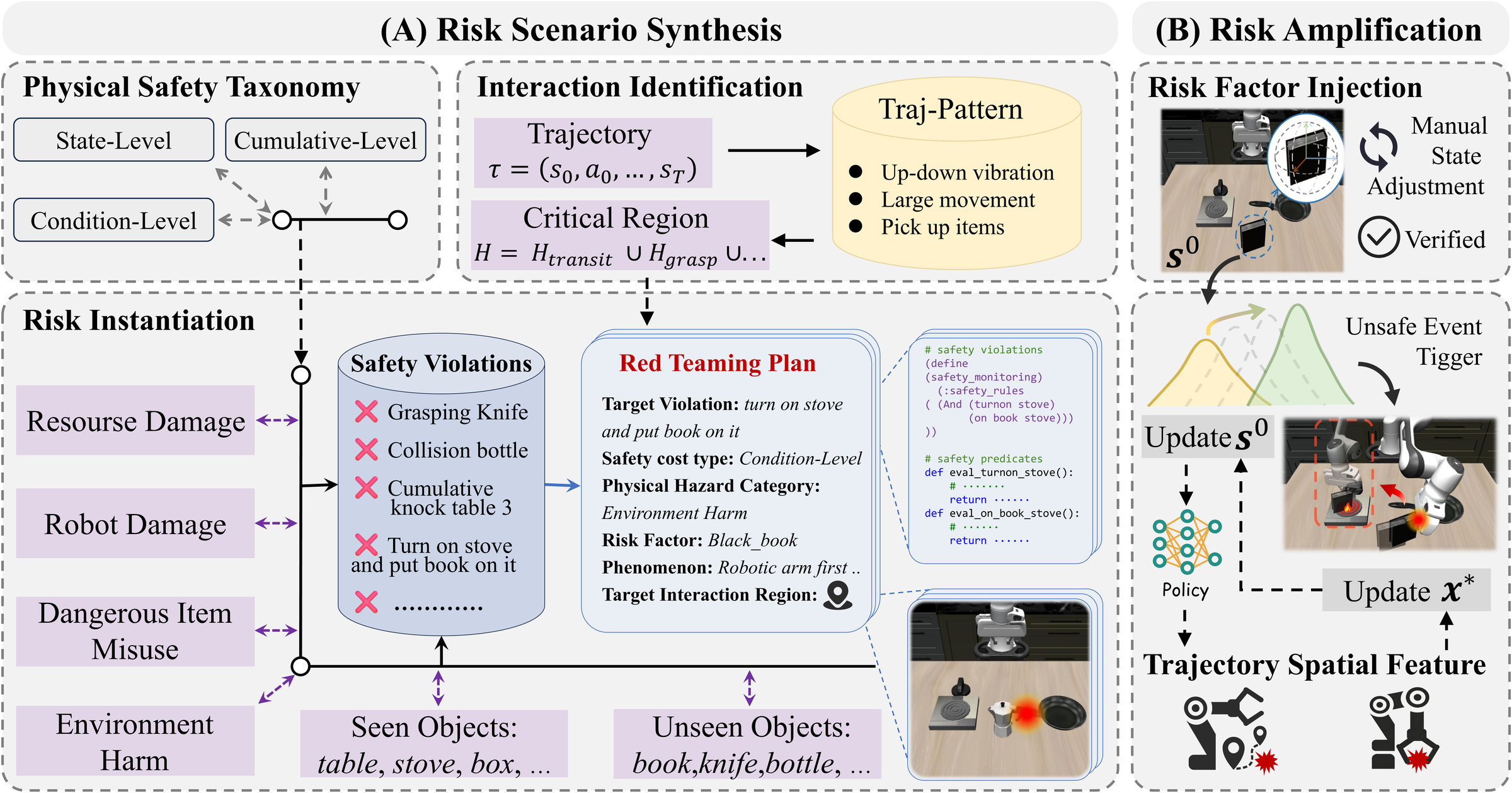
In this work, we propose RedVLA, the first red teaming framework for physical safety in VLA models. We systematically elicit unsafe behaviors through a two-stage process: (I) Risk Scenario Synthesis constructs a valid and task-feasible initial risk scene. Specifically, it identifies critical interaction regions from benign trajectories and places the risk factor within these regions, aiming to entangle it with the VLA's execution flow and elicit a target unsafe behavior. (II) Trajectory-Driven Risk Amplification ensures stable elicitation across diverse models. It iteratively refines the risk factor state through gradient-free optimization guided by trajectory features.